Note (Dec 5 2025): I do have some original thoughts in the “Some additional thoughts” section, but as for the rest, you should just watch Marcus Hutter’s 1 hour lecture if you want to understand Ilya’s talk. This post was written not long after I grasped the idea, so it’s not very polished, and, more importantly, I now find Ilya’s chain of reasoning a bit unnecessarily complicated. After all, it’s a simple idea. All the data that you, the observer, are given are the upstream and downstream datasets $X$ and $Y$, and as per the usual Solomonoff induction, you want to find the shortest program that generates $(X,Y)$ as the prefix. (Because that’s your prior. You believe that your history of observations is a partial output of a computer program, and future observations will be the rest of the output. Plus you assign higher prior to simpler computer programs.) It thus makes more sense to define $K(X,Y)$ as the objective, and Ilya’s detour to $K(Y \mid X)$ now seems a bit backwards.
In this post, I summarize Ilya Sutskever’s talk titled “An Observation on Generalization.” The talk is about a general theory of unsupervised learning, based on algorithmic information theory (AIT). Once I understood it, I realized that it’s answering a question that I’ve had for a long time without knowing how to properly phrase it. It took me quite some time to understand the idea, but it’s really very simple. The notations are kept the same as the original talk, to prevent any confusion.
TL;DR:
- We use algorithmic information theory to formalize the objective of unsupervised learning
Occam’s razor and AIT

Occam’s razor states that given some data, the best hypothesis (about how the data was generated) is the simplest hypothesis consistent with the data. But how can we formalize what it means to be simple or complex? We turn to algorithmic information theory (AIT) for the answer. Given a machine that can run programs written in 0s and 1s (i.e. a Universal Turing machine), a hypothesis that explains some data is equivalent to a program that outputs the data. The complexity of your hypothesis is the length of such a program.
Let me give you an example. Suppose we have a dataset $Y$ for a supervised learning task. So $Y$ looks like
\[\{ (u_1, w_1),\dots, (u_N, w_N) \}\]where $u_i$ and $w_i$ are the inputs and labels. Suppose we also have a probabilistic model $P$, such as a classifier with softmax outputs. Let’s turn this model into a program, or a hypothesis, that generates $Y$! Our program consists of three parts. First, all the inputs $ { u_1, \dots, u_N } $ are declared in the program. Then, the program applies $P$ to the inputs to obtain a predictive distribution $ p_i $ for each index $ i $. Finally, we use something like arithmetic coding to specify which are the correct labels $ w_i $. With an optimal coding scheme, labels that the model assigns high probability to will have shorter codes, meaning that the length of this “error-correcting” code will be proportional to the prediction error of the model (or cross-entropy, to be more precise).
Let’s think of the complexity of this program: it’s roughly the sum of the length of the inputs $ { u_1, \dots, u_N } $ (by length I mean their length in bits), the length of the code implementing $ P $, and the length of the code specifying the correct labels. Since the first part is a constant, the complexity of our program depends on the complexity of $P$, and its prediction error. This makes perfect sense! A good model is one that’s simple, and also accurate in describing our observation. We can also see how in the low-data regime, the complexity of $P$ dominates and it’s important to use simple models, while in the high-data regime, the complexity of $P$ becomes negligible compared to the prediction error, and we can care less about the model complexity.
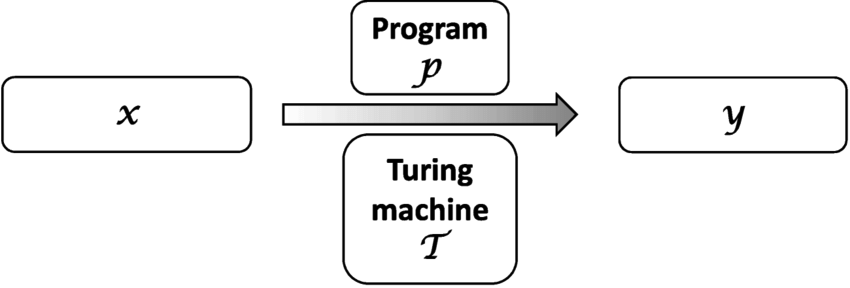
A program \( \mathcal P \), input \( x \), output \( y \), and Universal Turing machine (UTM) \( \mathcal T \).
Since the first part of the program is not relevant to a supervised learning task, we can simply make $ U = { u_1, \dots, u_N } $ an input to our program, so that our program can get it for free (without imposing additional bits in the program). Thus, finding a good supervised model $P$ is equivalent to finding the shortest program $\mathcal P$ that outputs $ W $ given the input $ U $. We call the length of this shortest program the Kolmogorov complexity of $W$ given $U$, and write it as $ K(W | U) $. Ilya doesn’t really talk about this to avoid complicating things, but $ K(Y) $ really should be written $K(W | U) $, because $K(Y)$ usually means $K(U, W)$. Basically, whenever you see “$Y$”, think of it as an abbreviation for “$ W | U $”. I will also abuse the notation and write $K(Y)$ for $K(W | U)$, and similarly, $K(Y, \dots | \dots)$ to mean $K(W, \dots | U, \dots )$.
Unsupervised learning
Above, we formalized supervised learning using Kolmogorov complexity. Can we do the same for unsupervised learning? Let’s think of all the components of unsupervised learning. We have an upstream dataset $X$, and a downstream supervised dataset $Y = (W | U)$. So we have these two datasets, but they can really be just concatenated into one big dataset, or observation. Again, by Occam’s razor, the best hypothesis for this observation should be the shortest program that outputs $\text{concat}(X, Y)$ (what I really mean is the shortest program that outputs $\text{concat}(X,W)$ given input $U$). There is a result in AIT that
\[K(X,Y) = K(X) + K(Y|X) + O(\log(K(X,Y))) .\]This says that using two programs, one that first outputs $X$ and another that outputs $Y$ given $X$, is about as compact as using one program that outputs $X$ and $Y$. Notice that $K(Y|X) \leq K(Y) $. In trying to explain $X$ and $Y$ together, we have found a shorter explanation for $Y$ that makes use of $X$. Intuitively, the program can extract regularities in $X$ that can be reused for describing $Y$. Since the ultimate goal of unsupervised learning is to make a good hypothesis $Y$ with the help of $X$, it makes sense to accept $K(Y|X)$ as the ultimate goal of unsupervised learning. The argument is quite hand-wavy, but can be made formal using Solomonoff induction and the idea of programs that output $\text{concat}(X,Y)$ as a prefix. To see this, I recommend you watching through Section 3 of Marcus Hutter’s “Introduction to Algorithmic Information Theory and University Learning”.
That’s great, we now have formalized unsupervised learning with
\[K(Y|X)\]Let me give you an example. We have a bunch of unlabelled images $X$, say the images from ImageNet. We want to learn a good model on the supervised dataset of image-label pairs $Y$, say CIFAR-10. One common way of doing unsupervised learning in this setting is to learn a representation using $X$, with SimCLR for example, and then learning a small linear layer or MLP on top of the representation with supervision of $Y$. (One could also finetune the representation mapping.) This can be turned into a program, that outputs $Y$ given $X$. This program first runs the representation learning procedure on $X$. Then, we should encode into the program the linear layer that goes on top of the learnt representation mapping. Finally, the error-correcting code is needed as usual, unless the cross-entropy is zero. The first part of the program has minimal length, as it only requires some code for backprop, etc. The second part needs the weights of the linear layer, which is much smaller than the full weight of a deep neural network. The third part depends on the prediction error. Note how this can dramatically reduce the program length when compared to $X$ was not available, in which case the full weights of the DNN would have to be coded into the program. In some sense, we have “extracted” much of the weights for free from the upstream dataset $X$, only requiring short codes for small adjustments such as linear layers, small MLP, or finetuning.
SGD as program search
Note how, in the usual supervised learning setting, we can use SGD on a neural network to find a decent program: one that isn’t too complex and also has low prediction error. You might ask, if two neural networks with zero prediction error are found, how can they have different complexities if their number of weights are the same? In other words, wouldn’t it take the same code lengths to encode the weights of two neural networks? The answer is simple: for every neural network, there are programs that behave the same, i.e. give the same outputs under the same inputs. Therefore, some neural networks are more compressible than others. To give an extreme example, imagine a hundred layer transformers with all weights set to zero. We can simply replace this neural network in our program with a function that just outputs zero for all inputs, taking less than a few bits of code. We can also think of a normal prior on weights or weight decay as a crude form of bias towards simple programs.
Whether SGD on neural networks is a good idea for finding simple programs is a complicated matter, but SGD tends to have simplicity biases, such as finding smooth functions, and most importantly, we have empirically seen their success in generalization, hinting at the possibility that it is a pretty good at searching for simple programs. This might sound like circular reasoning, but it really isn’t, if we have accepted as a universal fact that low complexity programs have stronger generalization. Soft or hard inductive biases in the neural network architecture can also bias the model towards simplicity.
Suppose we accept that SGD is a decent program search engine, and probably, the only decent one we’ve got that can operate on massive datasets like ImageNet. Then, something odd happens when we try to apply this to our unsupervised learning objective $K(Y|X)$. Neural networks can’t be conditioned on a huge dataset $X$. This is why we resort to the pipeline of learning representations from $X$ and finetuning them on $Y$. We can imagine a future machine more superior than our current neural networks, that can search over programs that receive as input $X$, including the programs that do representation learning and finetuning. But this simply isn’t what the current neural networks are designed for.
Then what can we do, with our current tools, that actually approximates this objective we’ve created for ourselves? Ilya proposes a simple solution: we can instead aim for $K(X,Y)$, which will contain a solution similar to $K(Y|X)$, due to the previous equation that relates $ K(X,Y) $ and $ K(Y|X) $. In other words, we can find with SGD a single monolithic model that models the probability distribution of both $X$ and $Y$. Perhaps the most straightforward way to do this would be to look at $X$ and $Y$ as bit-strings, and create a model that performs autoregressive predictions on both $X$ and $Y$, with an additional bit of input that tells the model whether it’s predicting inside $X$ or $Y$. What if we want to be able to train on a flexible range of $Y$, like it’s possible with representation learning methods? If continual learning actually worked, we would just train the model on $X$ and do some continual learning on $Y$. But this just isn’t the case, and we have to resort to finetuning on $Y$. If we agree that finetuning can serve, albeit very crudely, as a form of continual learning, we can then argue for the case that training on autoregressive prediction, self-supervised learning, or any task on $X$ that learns its probability distribution (which is essential for creating a program that outputs the dataset), and then finetuning the trained model on the downstream task $Y$, is the best we can currently do with respect to our theoretical objective $K(X,Y)$.
Some additional thoughts
We have seen how $K(Y|X)$ can serve as a theoretically well-motivated goal for unsupervised learning, although the theory has some limitations. The most notable limitation is that it doesn’t take into account the runtime of the program. If we had infinite compute, we could just retrain on $(X,Y)$ everytime for a new task $Y$. Actually, we could even do a brute force program search on some universal turing machine to find a very short program. The possibilities are endless. But given our mortal souls and finite compute budget, we just try our best to approximate the theoretical optimum.
Something to note here is that this theory points very precisely at which component we should minimize the complexity of. For instance, it doesn’t impose any preference on the complexity of the program search engine. It doesn’t matter if we use SGD, a brute force search, or a full-blown LLM to look for a program that describes our data. What matters is the complexity of the resulting program that they find. Information bottleneck theory is a very interesting theory that uses information theoretical concepts to explain what makes for a good, generalizable representation. Similarly, Yoshua Bengio thinks that a bottleneck in the working memory of humans leads to language-like representations which generalize well. These theories point at reducing the complexity of the representations, roughly speaking. AIT, on the other hand, advocates for reducing the complexity of the whole model, which can be seen as a more fundamental principle but lacking in its ability to explain what it means for a model to have a good representation (in fact, AIT doesn’t even assume that the model has to have a neural-network-like structure that has representations, etc.). One way to think of the two ideas is that the information bottleneck theory and similar theories regarding representations are logical consequences of AIT: learning generalizable representations leads to simpler prediction heads when compressing a dataset from a very large, general distributions, which in turn leads to simpler programs.
Understanding the idea of the talk made me start thinking about almost all the problems in artificial intelligence in terms of AIT. Here are some of the thoughts I’ve had:
Retrieval-augmented generation (RAG) is actually a program that receives as input a large corpus of text $X$ and uses it to perform predictions on $Y$. So RAG can also be considered an unsupervised learning method under our framework. How would RAG decrease the complexity from $K(Y)$ to $K(Y|X)$? The answer is simple: the model don’t need to memorize additional facts for $Y$ if those facts can be retrieved from $X$. Thus the additional parametric knowledge that would otherwise be required is relieved, reducing the model’s complexity.
François Chollet, in his famous paper “On Measure of Intelligence,” argues that current artificial intelligence systems lack flexible intelligence, which is the ability to acquire new skills, and instead are highly focused on crystallized intelligence, which is a measure of the skills that have already been acquired. He also advocates for a program synthesis approach, where upon seeing a few demonstrations on a task, the intelligent system synthesizes or searches for a program that can accomplish this task, with deep learning serving as a heuristics for the search. This approach has obvious theoretical advantages such as Turing completeness, sample efficiency and the ability to find extremely low complexity programs. The only problem is that it’s not scalable for complex tasks whose Kolmogorov complexity is inherently high. This might not be such a problem for the ARC challenge that he has put forward to serve as a measure of flexible intelligence, since the generative process of the problems there have extremely low complexity. This becomes especially problematic when we want to make use of a mass amount of prior observations $X$ to do well on task $Y$. SGD can effectively compress $X$ and $Y$ together to solve this problem, but program synthesis approach is inherently more tricky to implement because the $X$ might not have low complexity. One possible solution would be to compress $Y$ given $X$, by extracting a library of simple programs from $X$ to reuse for $Y$. (But how we can do this with a very large dataset $X$ is a largely unsolved problem.)
Although the proposed theory is largely impractical when we try to make technical predictions, it can say something about what makes for a good finetuning. In particular, it predicts that under the usual pretraining-finetuning framework, the code length required for adjusting the pretrained weights to fit to the downstream task is crucial. To be more precise, what matters is the shortest code required for adjusting the pretrained program to the finetuned program. One could predict how a finetuned model that required minimal change from the pretrained model will have good generalization. Techniques like LoRA or bias towards pretrained weights can be seen as a form of regularization for finetuning.